
Research and discoveries in cell biology have come a long way. Improvements in biological equipments, especially in the area of microscopy, have risen to a cutting-edge level. The precision in obtaining images on a microscopic scale is astonishing. These advances have now presented a challenge of obtaining a vast amount of image data in crispy-clear quality.
Although machine learning (ML) has resolved this problem with quick efficacy by using automation, it fails to utilise information from microscopic elements such as cells and tissues. ML only considers the properties or features surrounding the data. It does not dig in deep about the cellular features that determine or influence the extrinsic (environmental) factors have on humans.
In this article we will discuss a research analysis which shows that combining environmental and genetic features in an ML method improves the accuracy of a process called phenotyping. The accuracy in the recognition was found to be significantly high compared to regular ML-based phenotyping.
What Is Phenotyping?
Phenotyping is the process of predicting observations of the biochemical and physical characteristics of an organism, determined by the interactions of its genetic makeup and environment. Just like genotyping focuses on gathering information from the genes, phenotyping looks at the environmental factors that affect the genes.
Phenotyping has found wide applications in sub-branches of biology such as anatomy, histology among others, and has helped ascertain processes on a molecular scale. In fact, it is the primer for any kind of biomedical research.
The Setback In Molecular Data Analysis
As mentioned earlier, biological equipments have advanced largely in the field of microscopy. With them, data analysis in biology has also risen in parallel. But, biologists cite that data analysis alone cannot take account of both intrinsic as well as extrinsic factors on the bio-molecular level. They recommend that a proactive approach is needed to accommodate all the
In the latest study by a team of biological researchers from Hungarian Academy of Sciences, University of Szeged, Hungary and the University of Helsinki, Finland, they work on improving ML-assisted phenotyping by gathering all the cellular environmental factors that affect its function and then collaborating them in the learning method.
Supervised Machine Learning For Phenotyping
In the study, the researchers consider phenotyping details of single cells as the core idea. This is integrated with supervised ML. Now the cellular environmental features are extracted and tested to see how ‘cellular neighbourhood’ affects phenotyping. Various ML methods such as Random Forest, Naive Bayes, Sequential minimal optimisation and Multilayer Perceptron are used for evaluation.
Researchers then work on two types of datasets for the experiment. The first dataset consists of images from cell culture of breast cancer cells treated with different drugs (MCF-7 dataset), and the second dataset consists of images from tissue sections of cancerous urinary bladder collated by them (UBC dataset). Once these data are compiled, they use a proprietary software for ML. In their words,
“For the experiments, we used an image analysis and machine learning software (SCT Analyzer 1.0) developed by Single-Cell Technologies Ltd. (Szeged, Hungary). Versatile image pre-processing (illumination correction, filtering) and cell segmentation methods (including SLIC segmentation) are implemented in this software. An interactive interface helps the user to annotate segmented regions into an arbitrary number of phenotype classes. Numerous machine learning methods are available even for single-cell-level prediction. Last but not least, an active learning interface is provided to maximise user efficiency.”
After this, they segment the images using another software called CellProfiler to segregate cell features such as cell nuclei, cytoplasm, among other components vital in cellular neighbourhood consideration. Next, the features are extracted based on texture, intensity, shape etc. in the components. They use K-nearest neighbours and a distance-based approach to calculate neighbourhood features (for this purpose, they consider Euclidean distances in the components).
Once feature extraction is complete, it is ready for ML classification through the SCT Analyser system with respect to single cells. For this, the authors segregate the image dataset along nine phenotypic classes for MCF-7 dataset and eight classes for urinary bladder tissue sections. It is now subjected to different ML algorithm, which was mentioned earlier, to test the prediction performance along both with (neighbourhood distances) and without (local features) cellular neighbourhood factors.
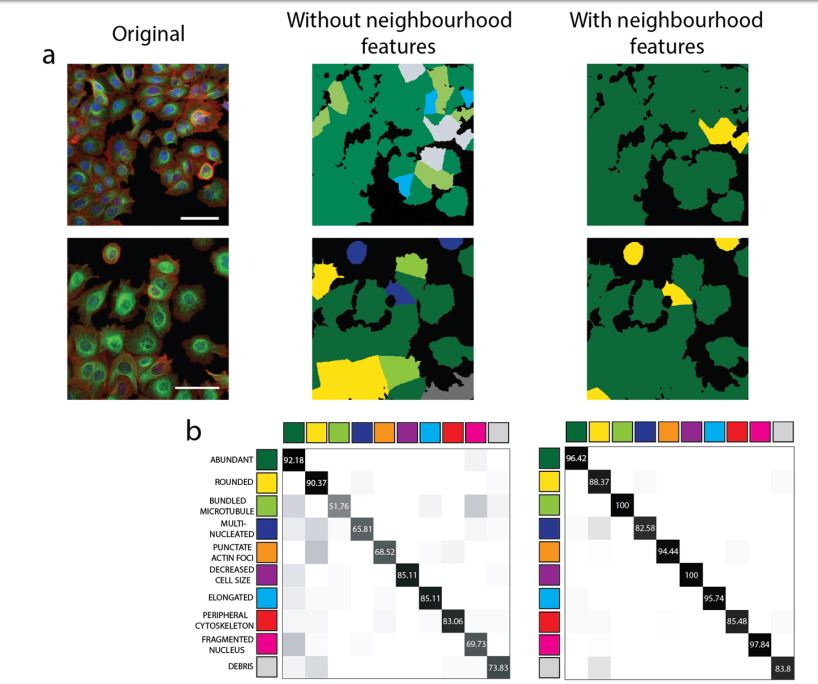
In the MCF-7 dataset, the accuracy is significantly improved in ML with an increase of 8 percent from previous studies. While the UBC dataset showed a rise in accuracy by an astonishing 19 percent.
Comments:
The positive results signify that as more cellular factors are considered, the recognition and prediction gets more accurate. Thus, the problem of accuracy can be mitigated in cells. The authors even contend that much more could be achieved through deep learning methods and their study will definitely act as a guiding beacon for future research.
The post How Cellular Features Improve ML Accuracy In Phenotyping appeared first on Analytics India Magazine.